A veces hay gente que piensa de manera muy original, saliendose del patrón habitual del pensamiento corriente, es el llamado pensamiento lateral. Os dejo con esta historia porque a mí la verdad que me ha dejado impresionado por la sencillez pero a la vez potencia de la solución que plantea.
Hace unos años, un ingeniero de la Carnegie Mellon University, Luis von Ahn, elaboró un método para mejorar la seguridad en las páginas webs.
El objetivo era evitar el uso abusivo de programas autmáticos que interactuaran con los formularios de una web. Había que buscar algo que un usuario pudiera hacer, pero fuera complicado para una máquina, con el fin de evitar que esta pudiera automatizar el proceso. Para ello, se le ocurrió poner una imagen generada de manera aleatoria, asociada al formulario de la web, de tal manera que si se quería enviar el formulario, se tenía que poner el contenido de esa imagen en un campo del formulario, algo sencillo para el ser humano (aunque no siempre), pero muy complicado para un ordenador por la complejidad de leer la información de esta imagen. Había inventado el CAPTCHA.
 |
| Ejemplo de CAPTCHA |
Sin embargo, se dió cuenta de que cada usuario, cada vez que introducía los valores de estas imagenes, perdía una media de 10 segundos por cada uno de ellos, por lo que al cabo del día multiplicado por los miles o millones de usuarios que utlizan los CAPTCHA, resultaba en una cantidad enorme de tiempo desaprovechado. ¿Cómo se podría aprovechar ese esfuerzo individual de manera colectiva?
Pues precisamente aprovechando la dificultad de la solución del problema. Es decir, si lo que hace que esa medida sea segura es que el ordenador no sabe leer esos textos, utilicemos ese esfuerzo de cada usuario para que el ordenador pueda leer textos.
Actualmente hay varios proyectos en marcha sobre digitalización de libros ( Google Books por ejemplo ), y uno de los principales problemas que se encuentran es que no son capaces de transformar las imagenes obtenidas desde el scanner a texto, ya sea por la calidad original del papel, bajo contraste o cualquier otro problema.
Por lo que la idea de este ingeniero ha sido reutilizar el esfuerzo.
Para ello utiliza dos imagenes, por un lado un CAPTCHA normal, generado de manera aleatoria que el usuario tendrá que escribir correctamente. Por otro lado la imagen digitalizada que el ordenador no es capaz de leer. Ambos se le muestran al usuario, que no sabe cual es cual, con lo cual para poder acceder a la web deberá introducir ambos correctamente, salvo que el único que será comprobado es aquel que fue generado por el ordenador, y el texto que el usuario introduce para la imagen que el ordenador no era capaz de reconocer será almacenado; de esta manera, finalmente, el ordenador eligirá aquella palabra más repetida entre todos los usuarios para esa imagen, pues será la más probable, y por tanto, se podrá digitalizar ese texto.
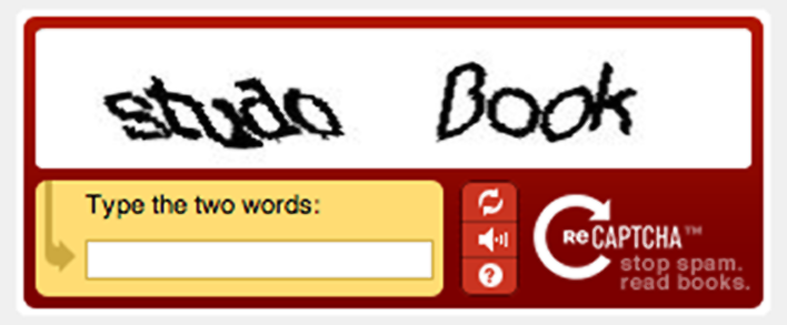 |
| Proyecto ReCAPTCHA |
Es decir, que en el momento que estás haciendo un CAPTCHA estás ayudando a la vez a digitalizar un libro. El usuario no lo nota, pero ese esfuerzo puede ser aprovechado.
Este y otro caso también interesante sobre como traducir la web de manera gratuita, son explicados por el propio Luis von Ahn en la siguiente charla TED. No os la perdais, está en inglés pero podeis ponerle subtítulos.
Como siempre, si te ha gustado, comparte esta entrada con los botones que aparecen debajo

No hay comentarios:
Publicar un comentario